The other day a colleague mentioned an interesting side-effect of CMAN: your clients never have to change the connection string ever again.
I’ve used CMAN for various other reasons (firewall channeling, etc.) but never thought of it as a solution to ever changing connection strings when you frequently move databases around. And from experience I can tell that for some application support teams changing connection strings can be a real struggle.
For this use case give the CMAN servers a round-robin DNS alias and publish service names that don’t need changing. This way, wherever your CMANs and databases are located the connection string for the client remains the same, e.g.:
1 2 3 4 5 6 7 8 9 10 11 | my_service = (DESCRIPTION = (FAILOVER = ON) (LOAD_BALANCE = OFF) (TRANSPORT_CONNECT_TIMEOUT = 3) (CONNECT_TIMEOUT = 6) (RETRY_COUNT = 1) (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = cmans)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = my_service)) ) |
So far everybody is happy…
Now, imagine you run Data Guard across two datacenters, A and B, for multiple databases. Some primary databases run in datacenter A, some in B. Because a few applications are extremely sensitive to latency, whenever a primary/standby role change happens you move your application server VMs to the same datacenter where the primary database runs.
Let’s introduce two CMAN instances in both datacenters and all of a sudden half your user base is complaining about performance. The problem is that about 50% of your connections are now going to the other datacenter just for CMAN to connect back, thus creating a loop:
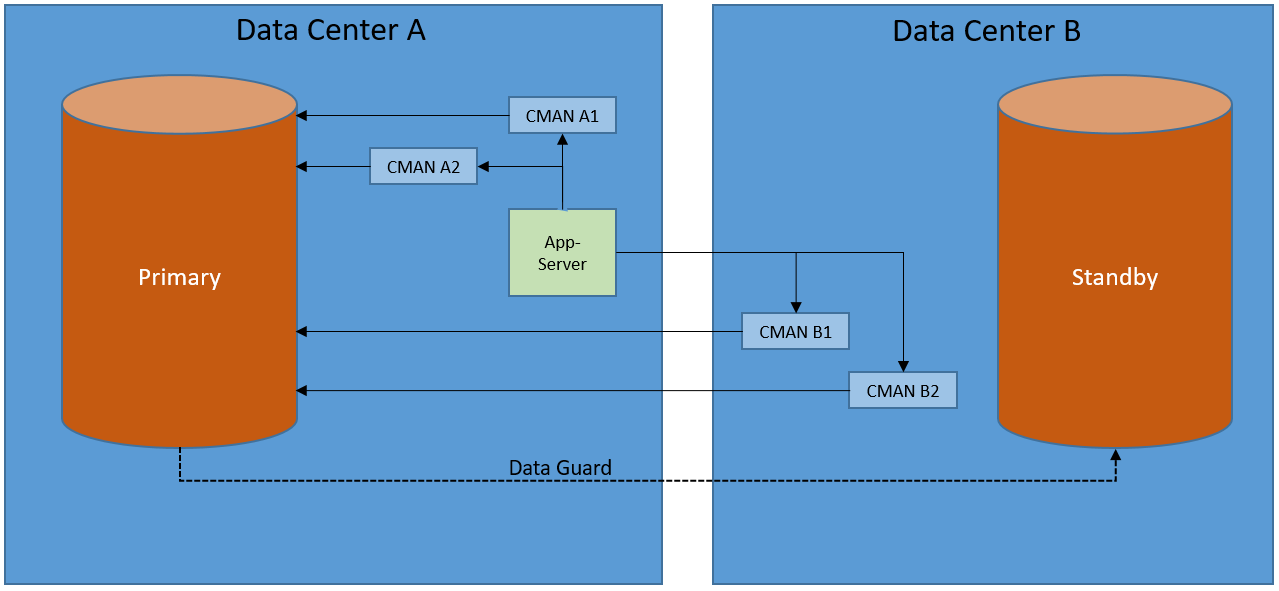
If your sole purpose for using CMAN is to avoid changing client connect strings there are probably other (read better) solutions, for instance OID TNS lookups.
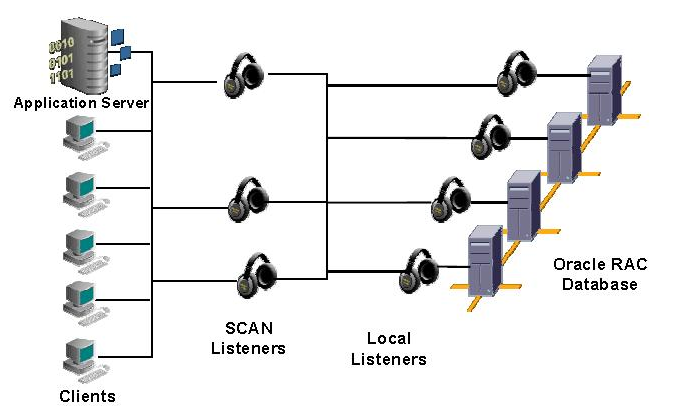
Or, hear me out, remote listeners 
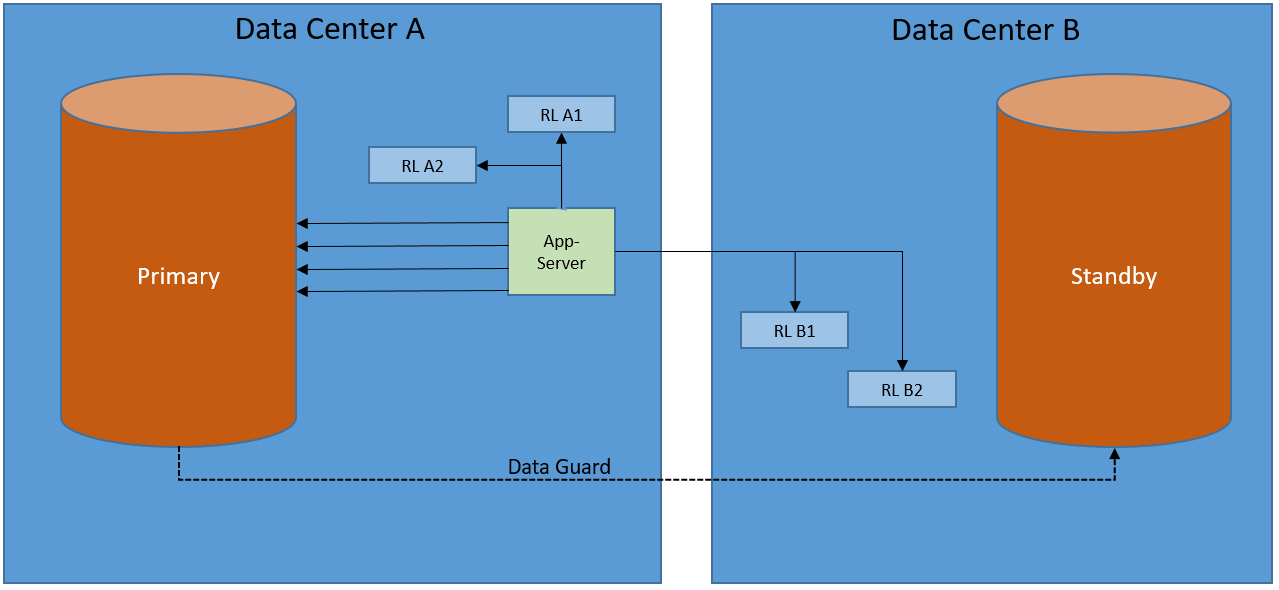
Replace CMAN with remote listeners to be the single point of contact for connection requests. The remote listener’s redirect messages will point to the local listener which will then spawn the server process. This way the application always connects to the database without being looped through the other datacenter. (for more details about listener redirects check this out)
How-to
For this example I’m assuming following hostnames, IPs, and DNS entries
DB server 1 in DC A: db-1 / 192.168.55.10
DB server 2 in DC B: db-2 / 192.168.55.20
Remote listeners in DC A: rl-1 / 192.168.55.30, rl-2 / 192.168.55.31
Remote listeners in DC B: rl-3 / 192.168.55.32, rl-4 / 192.168.55.33
DNS Alias: oracle-portal with IPs 192.168.55.30, 192.168.55.31, 192.168.55.32, 192.168.55.33 (round-robin for connection load balancing)
Create VMs/containers of the technology of your choosing and install the Oracle client.
1 2 3 4 5 6 7 8 9 10 11 12 | INVENTORY_LOCATION=/u01/app/oraInventoryORACLE_BASE=/u01/app/oracleORACLE_HOME=${ORACLE_BASE}/product/client19./runInstaller -silent -waitForCompletion -noconfig \oracle.install.responseFileVersion=/oracle/install/rspfmt_clientinstall_response_schema_v19.0.0 \UNIX_GROUP_NAME=oinstall \INVENTORY_LOCATION=${INVENTORY_LOCATION} \ORACLE_HOME=${ORACLE_HOME} \ORACLE_BASE=${ORACLE_BASE} \oracle.install.client.installType=Custom \oracle.install.client.customComponents=oracle.network.listener:19.0.0.0.0 |
Put this in ${ORACLE_HOME}/network/admin/listener.ora.
1 2 3 4 5 6 7 8 9 | LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rl-1)(PORT = 1521)) ) )ADMIN_RESTRICTIONS_LISTENER = ONVALID_NODE_CHECKING_REGISTRATION_LISTENER = ONREGISTRATION_INVITED_NODES_LISTENER = (rl-1, db-1, db-2) |
Start the listener.
1 | lsnrctl start LISTENER |
Repeat that for the other 3 remote listener VMs/containers (don’t forget to chenge the hostname in listener.ora).
Invited nodes (Valid Node Checking Registration) is a good security practice for listeners to restrict the hosts that can register services (remember CVE-2012-1675 and COST? What a drama this was  ).
).
Let the databases register their services.
1 2 | alter system set remote_listener = "rl-1:1521","rl-2:1521","rl-3:1521","rl-4:1521" scope=both sid='*';alter system register; |
That’s it. From now on, your clients no longer need to know on which server your database is running.
1 2 3 4 5 6 7 8 9 10 11 | my_service = (DESCRIPTION = (FAILOVER = ON) (LOAD_BALANCE = OFF) (TRANSPORT_CONNECT_TIMEOUT = 3) (CONNECT_TIMEOUT = 6) (RETRY_COUNT = 1) (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = oracle-portal)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = my_service)) ) |